この記事はRails Girls Japan Advent Calendar 2022の8日目の記事です。
昨日7日目はmurokacoさんの「デザイナーなりのRails Girls」でした。Tokyo 14thのオーガナイズ、お疲れさまでした!
また、この記事はRails Girls Japan Advent Calendar 2022 1日目の記事の続編となります。 もしかしたらそちらを先にご覧いただくとより楽しんでいただけるかもしれません。
自己紹介
だいたい仙台でソフトウェアエンジニアをしている あのぶる と申します。 Rails Girls関連のロールとしては以下のようなものを持っています。
そのほかのRubyコミュニティ関連のロールとして、Sendai.rbのスタッフもしています。
今回は、先日紹介した#rgjp10thお祝いツイートまとめの公式サイト掲載作業について書いていきたいと思います。
実は、先日のGatheringのLTタイトルとして最初出していたのはこの公式サイト実装の話だったのですが、こんな記事1本で収まらない話を何故LTで出来ると思ったのか、今となっては不思議で仕方ないです……
このフェーズでやった作業は「Firebase Realtime Databaseの構築」と「公式サイトに掲載」の2つです。調べものを含めて、プルリクエストを提出するまでの作業時間はだいたい5時間くらいでした。
Firebase Realtime Databaseの構築
FirebaseではデータベースとしてCloud FirestoreとRealtime Databaseの2つが提供されています。今回の要件としてはわりとどちらでもよかったのですが、ドキュメントにどちらを選ぶべきかを簡単に検討するためのチェックリストのようなものがあり、僅差でRealtime Databaseに軍配が上がったため、今回はそれに従うことにしました。
ユースケースを考えると圧倒的にread≫writeなのでその点に関してはCloud Firestoreの方に強みがあるようなのですが、どちらにしろツイートURLのリストなので、MB単位ならともかく数GBまでは行かないと思われるため、Realtime Databaseでも差し支えなかろうという判断をしています。
実際、今のところは後述する細かな実装上の不便以外は特に問題を感じていません。
使用するデータベースが決まればあとはコンソールから作業をしていきます。
やることは「プロジェクトの作成」「データベースの作成」「データの投入」「アプリケーションの作成(=認証情報の作成)」の4つ。 具体的な手順としては検索すると色々出てきますが、この辺の記事が参考になるかなと思います。
データベースの中身としては、今回はシンプルにツイートURLを配列として持たせたものを作りました。後述しますが、単純なリストってあんまりデータ構造として想定していないのか、微妙に使いづらいなという印象を持ちました。
初期データの投入は手元でJSONファイルを作っておいて、それをインポートさせるとやりやすいと思います。
公式サイトへの組み込み
まずはFirebase SDKと認証情報を管理するためのdotenvを追加します。
認証情報を.envファイルから読むように調整し、ダッシュボードからコピーしてきたスニペットを以下のような感じで調整します。
import { initializeApp } from "firebase/app"; import { getDatabase } from 'firebase/database' const firebaseConfig = { apiKey: process.env.FIREBASE_API_KEY, authDomain: process.env.FIREBASE_AUTH_DOMAIN, databaseURL: process.env.FIREBASE_DATABASE_URL, projectId: process.env.FIREBASE_PROJECT_ID, storageBucket: process.env.FIREBASE_STORAGE_BUCKET, messagingSenderId: process.env.FIREBASE_MESSAGING_SENDER_ID, appId: process.env.FIREBASE_APP_ID, }; const app = initializeApp(firebaseConfig); const database = getDatabase(app);
諸々設定を調整し、こんな感じのコード*1でFirebaseからデータを取得できたことを確認したらようやく組み込み作業。
ツイートの埋め込み自体はTwitter公式の埋め込みコードを使います。ただコピーするとたくさんのコードが出てくるのですが、たとえばこのツイート
Rails Girls 国内開催10周年記念特設サイト!#rgjp10th のツイートが表示されるようになりました!
— Rails Girls Japan (@RailsGirlsJapan) 2022年11月15日
みんなもツイートしてね! #railsgirls #railsgirlsjapanhttps://t.co/ZCdNFi6Vp5
を埋め込むために最低限必要な構成要素は↓の内容のみ。(もしかしたら<p>タグの属性も削除出来るかもしれませんが未確認)
<blockquote className="twitter-tweet" data-conversation="none"> <p lang="ja" dir="ltr"></p> <a href="https://twitter.com/RailsGirlsJapan/status/1592520803400445952"></a> </blockquote> <script async src="https://platform.twitter.com/widgets.js" charset="utf-8"></script>
ただ、最後の<script>タグが地味に曲者で、これを常に最後に読み込まないとツイートが正しく表示されません。
これが問題になるのが「もっとツイートを見る」ボタンのページネーションのタイミング。こればっかりは(少なくとも今の私の技術では)どうしようもないため、新しいツイート情報のロードが完了したタイミングでwidget.jsを読み込んでいた<script>タグを一旦削除し、appendし直すという作業を行っています。
ページネーションの実装でもう一つ問題になったのが先ほどの「Realtime Databaseってあんまり単純なリストのユースケースを想定していないのかも……?」という問題。
データベース上では古いツイートから新しいツイートの順に並べていてこれはそのままにしたい、でも表示の時は逆順にしたい。でもRealtime Databaseでは降順ソートに対応してなさそう……という問題に遭遇。この辺、Cloud Firestoreだとある程度検索の柔軟性が高いらしいので、もしかしたらそっちを使った方が良かったのかも?とは思いました。
が、調べてみたらやりようはあり、あんまり致命的な問題でもないのでそのまま進めることに。
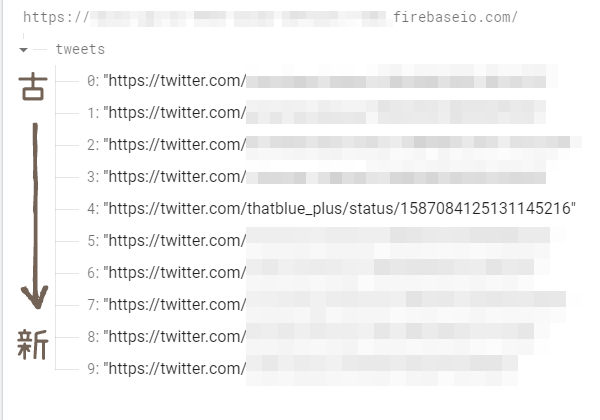
画像のとおり、Realtime Database内部では配列と言うよりは「0-based indexingっぽい連番の数字がキーになったオブジェクト」として管理されています。また、「N件目以前を取得する」「後ろからM件取得する」という条件は使えるため、一定件数ずつ取得したタイミングで範囲内の一番小さなインデックスの値を覚えておき、次の検索時に利用するというスタイルを取っています。
import { ref, query, get, orderByKey, limitToLast, endBefore, } from 'firebase/database'; get( query( ref(database, 'tweets'), orderByKey(), limitToLast(LOAD_COUNT), endBefore(currentIndex.toString(10)) ) ).then(() => {/* 取得したツイートを画面に表示する処理 */})
そして、この「配列のインデックスを意識しないといけない」という問題(?)が収集バッチにも影響していくのであった…!(と盛り上げるほど深刻な問題ではないです)
まとめと次回予告
ということで、公式サイトの掲載まで無事に進むことができました。次回はツイート収集バッチのお話をしようと思います。
天丼で申し訳ないのですが、#rgjp10th の記念ツイートは引き続き募集中ですのでよろしくお願いします🥰
明日はhsbtさんです!Gatheringでしていただいた、いい話のお話です!🥰 当日はスタッフ業でいっぱいいっぱいになっていてちゃんと聴けなかったのが悔やまれますが、とりあえずLEAN IN買いました。(まだ届かない)
*1:実際のコードのコピペではないので、もし動かなかったらすみません…